|
Nina Shvetsova
I am a fourth-year PhD student at the University of Tübingen (previously at Goethe University Frankfurt and the University of Bonn, following my advisor), advised by Prof. Hilde Kuehne, and a visiting PhD student at the Max Planck Institute for Informatics, advised by Prof. Bernt Schiele. As part of ELLIS PhD program, I'm also co-supervised by Prof. Christian Rupprecht, University of Oxford. I'm also participating in MIT-IBM Watson Sight and Sound Project.
My primary research area is deep learning for video and image understanding through self-supervised and multi-modal learning.
Before this, I received B.S. and M.S. degrees in Computer Science at the Moscow State University, where I worked on image anomaly detection, advised by Prof. Anton Konushin. During my master's, I also worked in Philips Research on medical image analysis.
Google Scholar /
Github /
LinkedIn /
Twitter
|

|
|
Featured Research
My current research interest lies in the field of self-supervised learning for video and image understanding, including multi-modal learning utilizing text and audio modalities.
|

|
M2SVid: End-to-End Inpainting and Refinement for Monocular-to-Stereo Video Conversion
Nina Shvetsova,
Goutam Bhat,
Prune Truong,
Hilde Kuehne,
Federico Tombari
Accepted to 3DV, 2026
project webpage /
arXiv /
bibtex /
code
|

|
Unbiasing through Textual Descriptions: Mitigating Representation Bias in Video Benchmarks
Nina Shvetsova,
Arsha Nagrani,
Bernt Schiele,
Hilde Kuehne,
Christian Rupprecht
CVPR, 2025
project webpage /
UTD dataset /
arXiv /
bibtex /
code
|

|
VideoGEM: Training-free Action Grounding in Videos
Felix Vogel,
Walid Bousselham,
Anna Kukleva,
Nina Shvetsova,
Hilde Kuehne
CVPR, 2025
arXiv /
bibtex /
code
|

|
HowToCaption: Prompting LLMs to Transform Video Annotations at Scale
Nina Shvetsova*,
Anna Kukleva*,
Xudong Hong,
Christian Rupprecht,
Bernt Schiele,
Hilde Kuehne (*equal contribution)
ECCV, 2024
paper /
supplement /
arXiv /
bibtex /
code
|

|
What, when, and where? Self-Supervised Spatio-Temporal Grounding in Untrimmed Multi-Action Videos from Narrated Instructions
Brian Chen,
Nina Shvetsova,
Andrew Rouditchenko,
Daniel Kondermann,
Samuel Thomas,
Shih-Fu Chang,
Rogerio S Feris,
James Glass,
Hilde Kuehne
CVPR, 2024
paper /
supplement /
arXiv /
bibtex /
code
|
|
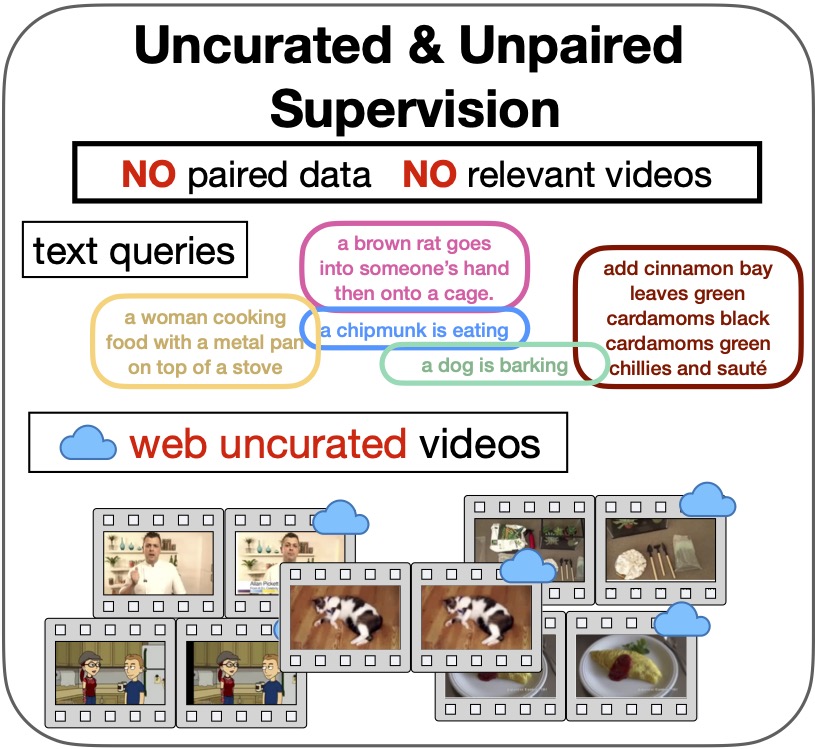
In-Style: Bridging Text and Uncurated Videos with Style Transfer for Text-Video Retrieval
Nina Shvetsova*,
Anna Kukleva*,
Bernt Schiele,
Hilde Kuehne (*equal contribution)
ICCV, 2023
paper /
supplement /
arXiv /
bibtex
|
|
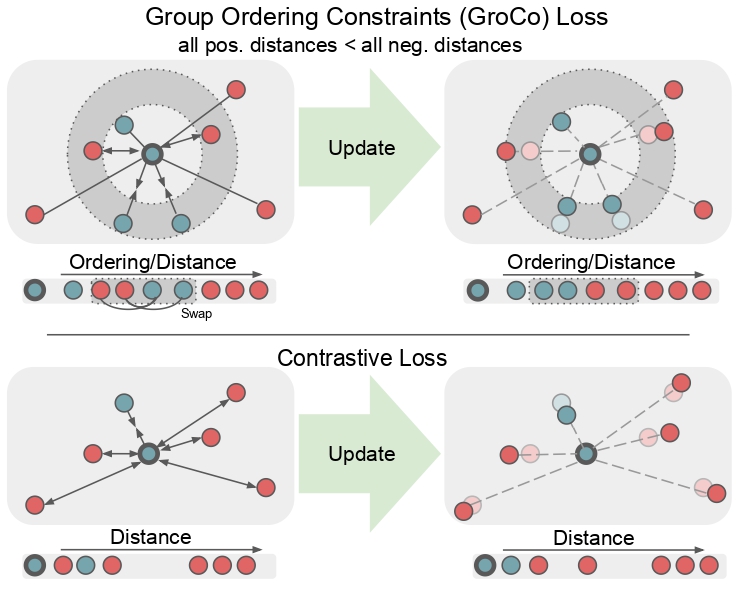
Learning by Sorting: Self-supervised Learning with Group Ordering Constraints
Nina Shvetsova,
Felix Petersen,
Anna Kukleva,
Bernt Schiele,
Hilde Kuehne,
ICCV, 2023
paper /
supplement /
arXiv /
bibtex /
code
|
|
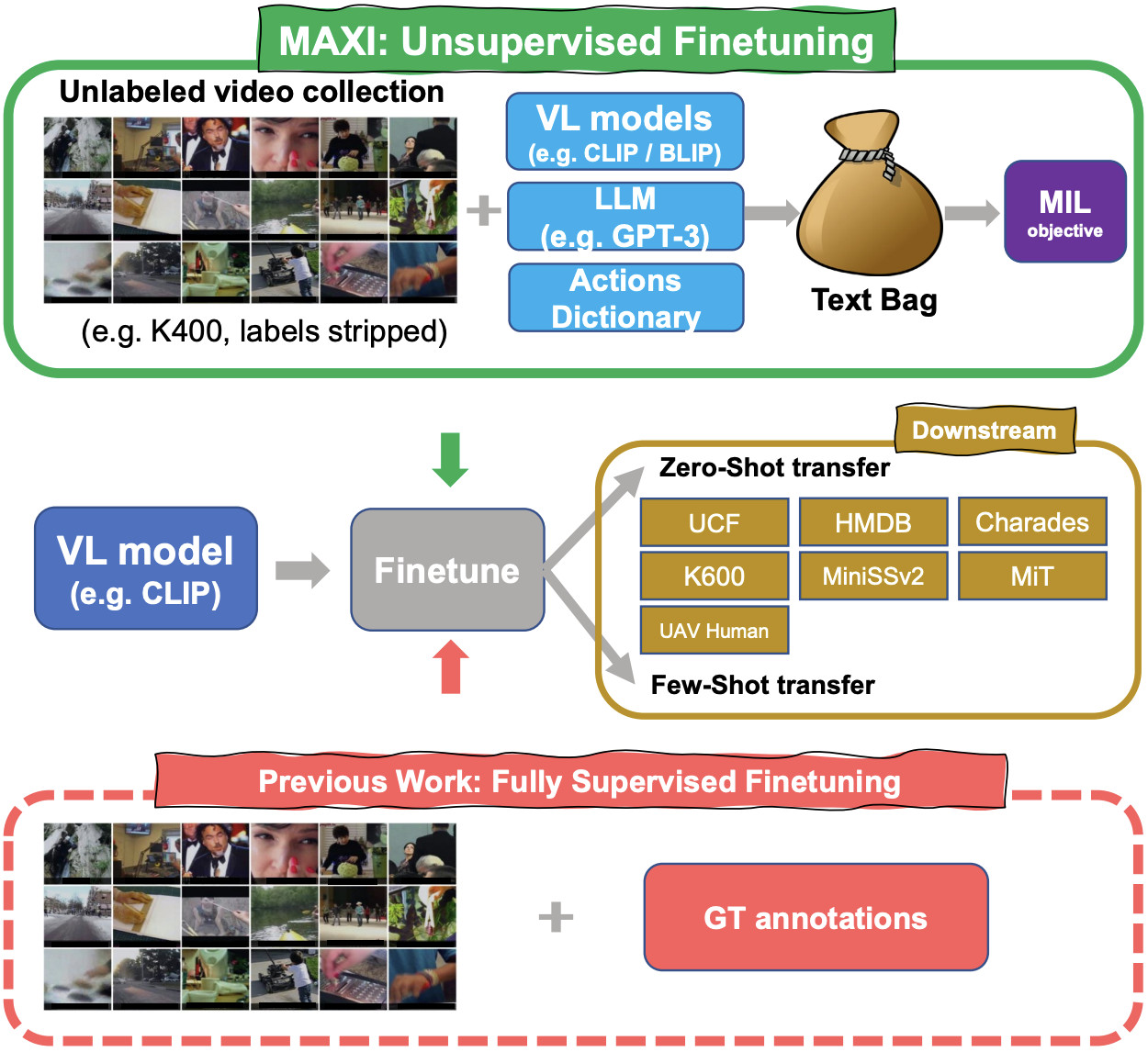
Match, expand and improve: Unsupervised finetuning for zero-shot action recognition with language knowledge
Wei Lin,
Leonid Karlinsky,
Nina Shvetsova,
Horst Possegger,
Mateusz Kozinski,
Rameswar Panda,
Rogerio Feris,
Hilde Kuehne,
Horst Bischof
ICCV, 2023
paper /
supplement /
arxiv /
bibtex /
code
|
|
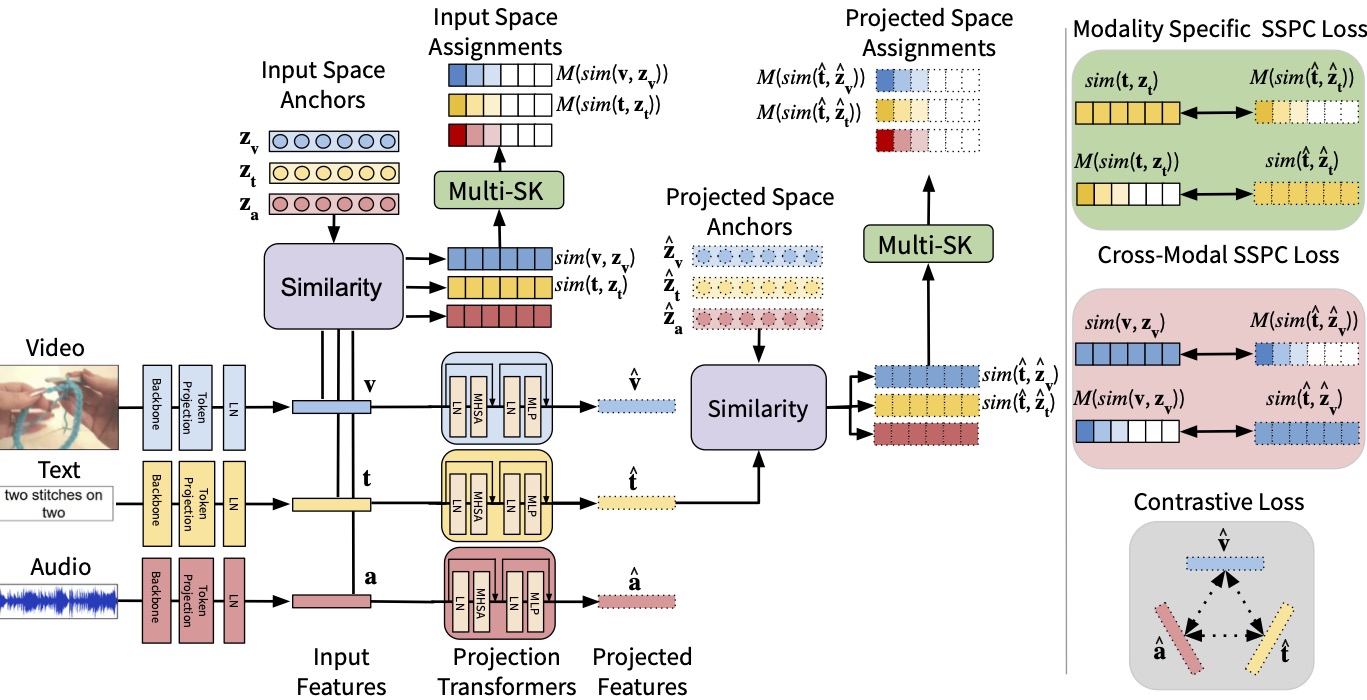
Preserving Modality Structure Improves Multi-Modal Learning
Sirnam Swetha,
Mamshad Nayeem Rizve,
Nina Shvetsova,
Hilde Kuehne,
Mubarak Shah
ICCV, 2023
paper /
supplement /
arxiv /
bibtex /
code
|
|
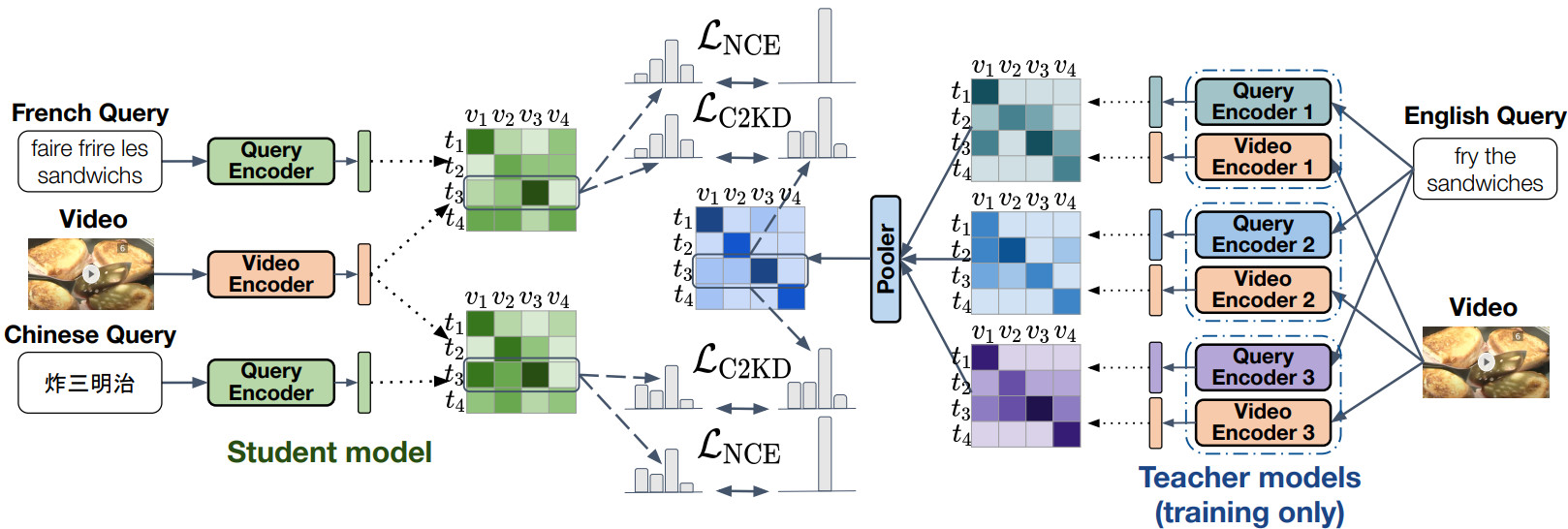
C2KD: Cross-Lingual Cross-Modal Knowledge Distillation for Multilingual Text-Video Retrieval
Andrew Rouditchenko,
Yung-Sung Chuang,
Nina Shvetsova,
Samuel Thomas,
Rogerio Feris,
Brian Kingsbury,
Leonid Karlinsky,
David Harwath,
Hilde Kuehne,
James Glass,
ICASSP , 2023
paper /
arXiv /
code
|

|
Everything at Once-Multi-Modal Fusion Transformer for Video Retrieval
Nina Shvetsova,
Brian Chen,
Andrew Rouditchenko,
Samuel Thomas,
Brian Kingsbury,
Rogerio S Feris,
David Harwath,
James Glass,
Hilde Kuehne,
CVPR, 2022
paper /
supplement /
arXiv /
bibtex /
code
Modality-agnostic self-attention blocks, trained on everything at once – all combinations of modalities, can produce a fused representation of any number of input modalities.
|
|
MOOD 2020: A public Benchmark for Out-of-Distribution Detection and Localization on medical Images
David Zimmerer, Peter M Full, Fabian Isensee, Paul Jäger, Tim Adler,
Jens Petersen, Gregor Köhler, Tobias Ross, Annika Reinke, Antanas Kascenas,
Bjørn Sand Jensen, Alison Q O’Neil, Jeremy Tan, Benjamin Hou, James Batten,
Huaqi Qiu, Bernhard Kainz,
Nina Shvetsova, Irina Fedulova, Dmitry V Dylov,
Baolun Yu, Jianyang Zhai, Jingtao Hu, Runxuan Si, Sihang Zhou, Siqi Wang, Xinyang Li,
Xuerun Chen, Yang Zhao, Sergio Naval Marimont, Giacomo Tarroni,
Victor Saase, Lena Maier-Hein, Klaus Maier-Hein
IEEE Transactions on Medical Imaging, 2022
paper /
bibtex /
code of our solution
|

|
Routing with Self-Attention for Multimodal Capsule Networks
Kevin Duarte,
Brian Chen,
Nina Shvetsova,
Andrew Rouditchenko,
Samuel Thomas,
Alexander Liu,
David Harwath,
James Glass,
Hilde Kuehne,
Mubarak Shah,
arxiv, 2021
arXiv /
bibtex
Qualities of capsule architectures is used in the context of multimodal learning to learn similar concepts across different modalities.
|
|
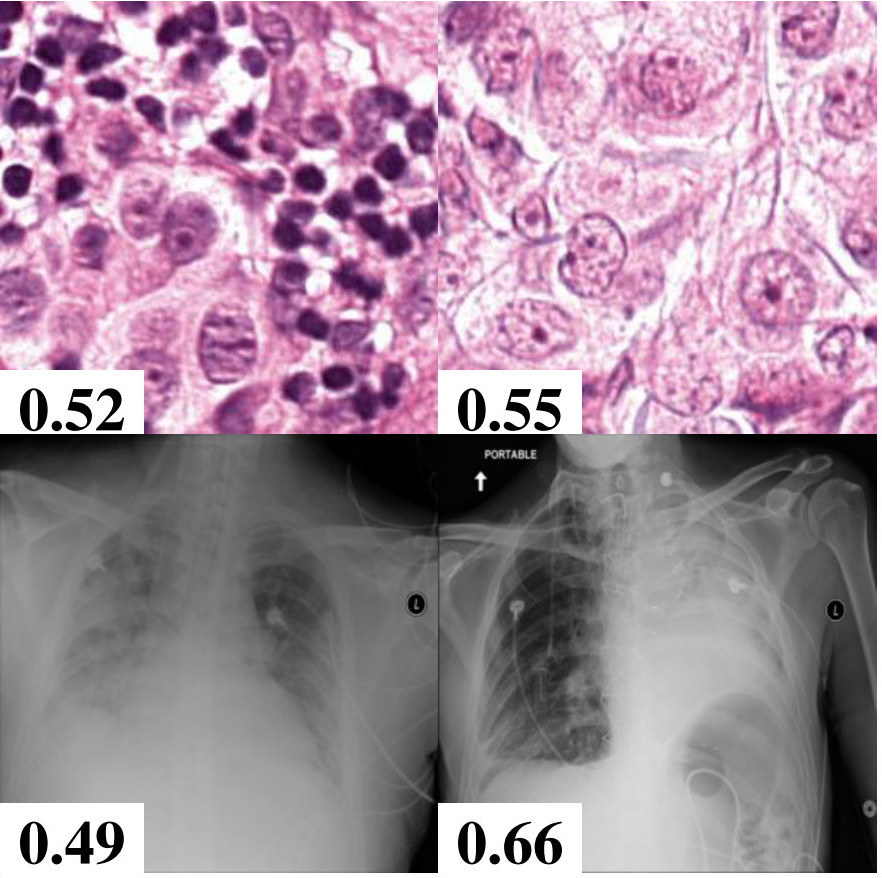
Anomaly Detection in Medical Imaging with Deep Perceptual Autoencoders
Nina Shvetsova,
Bart Bakker,
Irina Fedulova,
Heirich Schulz,
Dmitry V. Dylov
IEEE Access, 2021
paper /
arXiv /
bibtex /
code
We establish a strong baseline in anomaly detection in medical images by extending deep autoencoder with progressive growing training to handle high-resolution, complex images.
|

|
Perceptual Image Anomaly Detection
Nina Tuluptceva,
Bart Bakker,
Irina Fedulova,
Anton Konushin
ACPR, 2019
paper /
arXiv /
bibtex /
code
We present a novel method for image anomaly detection leveraging Generative Adversarial Networks to map an image distribution to a predefined latent distribution and vice versa.
This paper took IAPR Best Paper Award at ACPR’19
|
|